はじめに
多変量データは実世界の様々なところで現れる(e.g., 画像、音声、動画).これらの多変量データの多くは、データ自体がもつ次元 (e.g., ピクセル数)よりも小さい次元(自然画像の多様体的なやつ)で表現することができる. データから低次元の構造(低ランク行列)を取り出す代表的な方法として、PCAがある. しかし、実世界で観測されるデータには外れ値が含まれていることが多く、PCAはこの外れ値の影響を強く受けて低ランク行列を求めてしまうという性質がある. 外れ値にロバストに低ランク行列を推定する方法 (a.k.a., robust PCA)として、Principal Component Pursuitが提案されている. ここではPCPの簡単な説明と実装を行い、PCAと比較する.
低ランク行列
なんらかの低ランクな構造を持っている(日本語あやしい)多変量データは低ランクな行列
とノイズ
の和としてかける.ここで、
はデータ数、
は各データの次元を表す.
ここでは例として、MNISTのデータをとして、低ランクな行列
を求める問題を考える.
データのダウンロードなどは以下. 最近scikit-learnのMNIST downloadはうまくいかないらしいので,こちらを参考にしてダウンロードした.(いつのまにかdeprecatedになっていた)
以降ではの平均は0であるとする.
import numpy as np import pylab as plt from sklearn.decomposition import PCA from sklearn import datasets %matplotlib inline
import urllib.request import os.path url_base = 'http://yann.lecun.com/exdb/mnist/' key_file = { 'train_img':'train-images-idx3-ubyte.gz', 'train_label':'train-labels-idx1-ubyte.gz', 'test_img':'t10k-images-idx3-ubyte.gz', 'test_label':'t10k-labels-idx1-ubyte.gz' } dataset_dir = "." def _download(filename): file_path = dataset_dir + '/' + filename if os.path.exists(file_path): return print('already exist') print('Downloading ' + filename + ' ...') urllib.request.urlretrieve(url_base + filename, file_path) print('Done') def download_mnist(): for v in key_file.values(): _download(v) download_mnist()
def load_mnist(filename): img_size = 28**2 file_path = dataset_dir + '/' + filename with gzip.open(file_path, 'rb') as f: data = np.frombuffer(f.read(), np.uint8, offset=16) return data.reshape(-1, img_size)
import gzip nb_samples = 3000 data = load_mnist(key_file['train_img'])[:nb_samples] data = data/255 img1 = data[0].reshape(28, 28) import pylab as plt plt.imshow(img1)

with gzip.open(key_file["train_label"], 'rb') as f: labels = np.frombuffer(f.read(), np.uint8, offset=8)[:nb_samples] labels.shape
(3000,)
X = data - data.mean(axis=0)
plt.pcolormesh(X) plt.show()

PCA
PCAではノイズとして、ガウス分布から発生するノイズを考えて、以下のような最適化問題によって低ランク行列
を求める.(実際にPCAすると"分散が最大になる方向"に軸を置き直すが、その部分は今は考えずに、低ランクに近似、つまり次元削減の部分にのみ着目する.)
ここではフロベニウスノルム.
つまり、PCAはl2の意味でデータ
に最も"近い"低ランク行列
を求めているといえる.
この問題は
を特異値分解することで、以下のように
を求める方法が知られている.
ここで
であり、
は特異値
のうち、大きい方から
個を対角要素に並べた行列.
はそれに対応した行,列を抜き出したもの.
from numpy.linalg import svd u, Σ , vh = svd(X, full_matrices=False) L = (u[:,:2] @ np.diag(Σ[:2]) @ vh[:2])
plt.pcolormesh(L) plt.show()

ジャギジャギしていたデータがなんか綺麗になっていて,なんとなく二次元ぐらいで表現されているような気がする (適当). ここままだと見にくいので,PCAと同じようにデータを特異ベクトル(特異値が大きいほうから2次元)の方向へ射影して散布図として表現すると以下のようになる.
L_d = X @ np.transpose(vh) plt.scatter(L_d[:,0], L_d[:,1], marker=".", c=labels, cmap="jet") plt.show()

これは(決まらない符号を除いて,) scikit learnのPCAによって求まるものと全く同じになる. そもそもscikit-learnのPCAはSVDで解かれている
pca = PCA() pcaed = pca.fit_transform(data) plt.scatter(pcaed[:,0], pcaed[:,1], marker=".", c=labels, cmap="jet") plt.show()
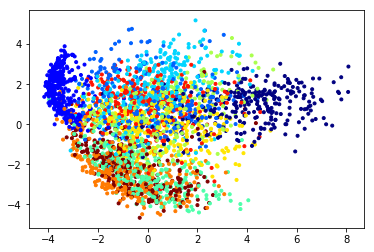
外れ値が含まれるデータに対するPCA
ここでデータに外れ値が含まれている場合を考える. 例として、MNISTに含まれるデータのうち、1ピクセルが他のピクセルよりも大きめのランダムな値であるとする.
# data[0] = np.random.randn(784) * 4 data[0, 0] = 100 X = data - data.mean(axis=0) u, s, vh = svd(X, full_matrices=False)
L_d_with_noise = X @ np.transpose(vh)
plt.scatter(L_d_with_noise[:,0], L_d_with_noise[:,1], marker=".", c=labels, cmap="jet") plt.show()

このようにPCAでは少ない数の外れ値に大きく影響された射影が得られてしまうことがある.
Principal Component Pursuit
外れ値は現実のデータにおいてよく現れるが、データに含まれる構造を見たいという目的で低ランク近似をしていた場合、少ない数の外れ値に大きく影響された結果は望ましくない.
そこで、外れ値の存在を考慮して低ランク行列を求めるアルゴリズム(Principal Component Pursuit)が提案されている.
ここで外れ値をと書く.外れ値は全体の一部であるとして、
はスパースな行列であると仮定する.
Principal Component Pursuitでは、行列
を以下のように表すことができると考える.
スパース制約をナイーブに考えるとのl0ノルムを小さくしつつ、
を求める必要があるが、この問題はNP-hardなので難しい.
そこで、PCPでは以下の緩和した問題を考える.
ここではトレースノルム(特異値の和)であり,
はl1ノルム.
この制約付き最適化問題は拡張ラグランジュ法を用いて解くことができる.
PCPの論文ではこの緩和した問題を解くことで得られる
がいくつかの仮定のもとで、はじめの最適化問題の解と一致することを示している (証明ちゃんと読んでないのでたぶん).
仮定の1つとして(??)、パラメータ
が以下の値であるとしている.
、ここで、
である
以上から、PCPを実装すると以下のようになる.
X = data X.shape
(3000, 784)
S = 0 Y = 0 μ = 2 λ = 1/(max(X.shape))**0.5 print(λ) nb_epochs = 100
0.018257418583505537
def shrink(x, τ): shape = x.shape x = x.reshape(-1) temp = np.apply_along_axis(lambda a: np.max(np.c_[np.abs(a)-τ, np.zeros(len(a))], axis=1), 0, x) return np.sign(x.reshape(shape)) * temp.reshape(shape)
from tqdm import tqdm hist_normY = [] for i in tqdm(range(nb_epochs)): u, Σ, vh = np.linalg.svd(X - S + Y/μ, full_matrices=False) L = np.matmul(u * shrink(Σ, 1/μ), vh) S = shrink(X - L + Y/μ, λ/μ) Y = Y + μ*(X - L - S)
100%|██████████| 100/100 [00:57<00:00, 1.73it/s]
plt.scatter(S[:,0], S[:,1], marker=".", c=labels) plt.show()

L_d_PCP = (X - S - Y)@ np.transpose(vh)
結果
- PCPで求めた低ランク行列
plt.scatter(L_d_PCP[:,0], L_d_PCP[:,1], marker=".", c=labels, cmap="jet") plt.show()

- ノイズがない場合のPCAの結果
plt.scatter(L_d[:,0], L_d[:,1], marker=".", c=labels, cmap="jet") plt.show()

- ノイズがある場合のPCAの結果
plt.scatter(L_d_with_noise[:,0], L_d_with_noise[:,1], marker=".", c=labels, cmap="jet") plt.show()

おわりに
外れ値にロバストなPCAとして、Principal Component Pursuitの実装を行った. PCAを行列の低ランク近似だと思うと、スパースな外れ値がのったモデルを考えるのは妥当であるように思える. 実装した結果を見ても、きちんと外れ値を推定することができていた. 今回はMNISTに適当なノイズをのせたデータを用いたが、論文には実際の動画データに適用した例もある(長時間映っている背景部分が低ランク行列で表現され、移動している人が外れ値になる).
この論文はむちゃくちゃ引用されており、Robust Principal Component Pursuitなど(まだロバストにしたいのか)色々発展もありそうなので、チェックしてみたい.
参考
- Robust Principal Component Aanalysis?
- 機械学習のための連続最適化
- Robust Principal Component Pursuit
- mldata.org is down (for good?) #8588
- Python - MNISTを使う - LOGICKY BLOG
- https://github.com/scikit-learn/scikit-learn/blob/master/sklearn/datasets/mldata.py
- PCAとSVDの関連について - Qiita
- scikit-learn/pca.py at bac89c253b35a8f1a3827389fbee0f5bebcbc985 · scikit-learn/scikit-learn · GitHub