はじめに
ガウス過程と機械学習を読んだ.
この記事では自分の理解のために,ガウス過程を実装する.
notebookはこっちにある.
github.com
今のところの理解では,$N_1$個の入力と出力のペア$(x_1^{(1)}, y_1^{(1)}),\dots ,(x_{1}^{(N_1)}, y_{1}^{(N_1)})$と,出力を求めたい$N_2$個の入力$(x_2^{(1)}, y_2^{(1)}),\dots ,(x_{2}^{(N_2)}, y_{2}^{(N_2)})$があるとき,ガウス過程では以下のようにして出力$y_2$の分布を求める.
- 観測$y_1\in \mathbb R^{N_1}$および$y_2 \in \mathbb R^{N_2}$がある1つの多変量ガウス分布に従うとする.$y = [y_1, y_2]^\top$, $x = [x_1, x_2]^\top$とするとき,$y(\mu(x), S(x))$ $y = \mathcal{N}(\mu(x), S(x))$.ここで,平均$\mu$および分散$S$は$x$の関数1.
- $y_1$が得られたときの,$y_2$の条件付き確率分布を求める.
以下では,平均気温の変動を例に実際にガウス過程を書いてみる.
気温変動の例
この記事では例として以下のような愛知県の気温の変動について考える.
データは気象庁のHPから入手できる.
はじめに簡単な例として,ある日の気温$y_1$が観測されたときに,次の日の気温$y_2$の確率分布を求める問題を考える.
とりあえず,$y_1$と$y_2$の関係をプロットすると以下.
%matplotlib inline
import numpy as np
import pylab as plt
import pandas as pd
import seaborn as sns
from scipy.stats import multivariate_normal
from random import shuffle
from tqdm import tqdm_notebook as tqdm
data = pd.read_csv("./data.csv")
data.head()
|
年月日 |
平均気温 |
Unnamed: 2 |
Unnamed: 3 |
| 0 |
2016/8/1 |
27.9 |
8 |
1 |
| 1 |
2016/8/2 |
26.5 |
8 |
1 |
| 2 |
2016/8/3 |
27.9 |
8 |
1 |
| 3 |
2016/8/4 |
29.0 |
8 |
1 |
| 4 |
2016/8/5 |
29.3 |
8 |
1 |
data = pd.read_csv("./data.csv")
data["年月日"] = pd.to_datetime(data["年月日"])
data = data[data["年月日"] < "2018/8/2"]
temperatures = data.values[:, 1].astype(np.float32)
plt.figure(figsize=(6,6))
plt.scatter(temperatures[:-1],temperatures[1:], alpha=0.3, linewidths=0, marker=".", c="gray")
plt.xlabel("$y_1$")
plt.ylabel("$Y_2$")
plt.show()

散布図よりある日の気温と次の日の気温が相関していることがわかる.
また,全体的に気温の分布はガウス分布っぽくなっている(ということにする).
以上から,ある日と次の日の気温の分布は多変量ガウス分布$p(y_1, y_2) = \mathcal{N}(\bar{y}, S)$によってモデル化することができそうである.
ここで,$\bar{y} \in \mathbb R^{2}$は年間の気温の平均$\bar{y}$を並べたベクトルであり,$S$は分散共分散行列である.
mean_temperature = np.mean(temperatures)
cov_temperatures = np.cov(np.c_[temperatures[:-1], temperatures[1:]], rowvar=0)
Sigma11, Sigma12, Sigma21, Sigma22 = cov_temperatures.reshape(-1)
display(mean_temperature)
display(cov_temperatures)
16.492613
array([[76.93262956, 75.43887714],
[75.43887714, 77.04298053]])
データより平均は16ぐらい.
分散共分散行列の成分$S_{11}, S_{22}$はともに年間の気温の分散であり,データより$S_{11}, S_{22} = 77$ぐらいで,共分散$S_{12} = S_{21} = 75$ぐらいであった.
データを多変量ガウス分布でモデル化するのが妥当かをなんとなく見るために,この多変量ガウス分布とデータの分布を比較すると以下のようになる.
x = np.linspace(np.min(temperatures)-5,np.max(temperatures)+5)
y = np.linspace(np.min(temperatures)-5,np.max(temperatures)+5)
XX, YY = np.meshgrid(x,y)
shape = XX.shape
XX = XX.reshape(-1)
YY = YY.reshape(-1)
plt.figure(figsize=(12,6))
plt.subplot(121)
plt.title("data distribution")
sns.kdeplot(temperatures[1:], temperatures[:-1], shade=True, cmap="viridis")
plt.scatter(temperatures[1:], temperatures[:-1],
alpha=0.3, linewidths=0, marker=".", c="gray")
plt.subplot(122)
plt.title("multivariate gaussian")
plt.contourf(XX.reshape(shape), YY.reshape(shape),
multivariate_normal.pdf(np.array(list(zip(XX, YY))),
mean=[mean_temperature,mean_temperature],
cov=cov_temperatures).reshape(shape))
plt.scatter(temperatures[1:], temperatures[:-1],
alpha=0.3, linewidths=0, marker=".", c="gray")
plt.show()

(日本の気温は夏と冬で二極化しているので,ガウス分布ではない気もするが) 今回はこれで良しとする.
ある日の気温$y_1$と次の日の気温$y_2$の同時分布をモデル化することはできた.
次に,ある日の気温$y_1$が観測されたときの次の日の気温$y_2$の確率,つまり,条件付き確率$p(y_1| y_2) $を考える.
$y_1$が観測されたとき,$y_2$の条件付き確率は
$p(y_2 | y_1) = \mathcal{N}(S_{21}S_{11}^{-1}(y_1-\bar{y}) + \bar{y}, S_{22} - S_{21}S_{11^{-1}}S_{12})$
で与えられる.
from scipy.stats import norm
def conditional_pdf(y1, mean, range_y2=np.arange(-3, 3, 0.1)):
mean = Sigma21/Sigma11*y1 + mean
variance = Sigma22 - Sigma21 / Sigma11 * Sigma12
return range_y2, norm.pdf(range_y2, loc=mean, scale=variance) * 30
プロットでこれが結局どのような分布なのかを確認する.
例として,今日の気温が25℃,15℃,5℃であったときの$p(y_2|y_1)$を以下に示す.
plt.figure(figsize=(6,6))
plt.scatter(temperatures[1:], temperatures[:-1],
alpha=0.3, linewidths=0, marker=".", c="gray")
plt.contour(XX.reshape(shape), YY.reshape(shape),
multivariate_normal.pdf(np.array(list(zip(XX, YY))),
mean=[mean_temperature,mean_temperature],
cov=cov_temperatures).reshape(shape))
for i in np.linspace(5, 25, 3):
range_y2, pdf = conditional_pdf(i - mean_temperature,
mean_temperature,
range_y2=np.linspace(np.min(temperatures)-5, np.max(temperatures)+5,100))
plt.plot(pdf+i, range_y2, c="C0", alpha=0.8)
plt.axis("equal")
plt.xlabel("$y_1$")
plt.ylabel("$y_2$")
plt.show()

ガウス分布では$S_{11}$と$S_{21}$が近い値になっているため,$y_1$がある値をとったとき,$y_2$はその値の近くを中心とするガウス分布になることがわかる.
こんな感じで,観測できた変数$y_1$と知りたい値$y_2$(今回は重複していているけど)を1つの多変量ガウス分布でモデル化することができれば,条件付き確率を求めることで,知りたい値$y_2$の分布を求めることができる.
ここまではある日の気温から次の日の気温を予測する問題を考えてきた.
次にこの問題を少し一般化して,観測できた複数の日の気温$y_1$を使って,期間中の全ての日の気温$y_2$をモデル化する問題を考える.
ids = data.index.values
shuffle(ids)
observed_ids = np.array(sorted(ids[:400]))
data = data.iloc[observed_ids].sort_values("年月日")
y1 = data.values[:, 1].astype(np.float32)
mean_temp = y1.mean()
x1 = observed_ids
x2 = list(set(ids) - set(x1))
xs = np.r_[x1, x2]
data.head()
|
年月日 |
平均気温 |
Unnamed: 2 |
Unnamed: 3 |
| 186 |
2016-08-02 |
26.5 |
8 |
1 |
| 517 |
2016-08-03 |
27.9 |
8 |
1 |
| 144 |
2016-08-04 |
29.0 |
8 |
1 |
| 527 |
2016-08-05 |
29.3 |
8 |
1 |
| 422 |
2016-08-06 |
29.8 |
8 |
1 |
観測,予測したい日が複数であった場合にも先ほどと同様に1つの多変量ガウス分布でこれらの同時分布をモデル化する.
今回は$y_2$の平均は$y_1$の平均と同じということにする.
先程の例ではデータから共分散の値を求めていたが,今回は以下のような行列を使ってモデル化する.
$$S(x) = K(x; \theta_1, \theta_2) + \theta_3 \mathbb I$$
ここで,$x$は入力,今回の場合は日付(2016/8/1を0とした)である.
$K(x; \theta_1, \theta_2)$はカーネル行列であり$K_{nn'}(x_n, x_{n'}; \theta_1, \theta_2) = k(x_n, x_{n'};\theta_1, \theta_2)$,また,今回はガウスカーネル$k(x_n, x_{n'};\theta_1, \theta_2) = \theta_1 \mathrm{exp}\left(- \frac{|x_n - x_{n'}|}{\theta2} \right)$を用いる.
$\theta3$は観測のノイズを表す2.
import torch
from torch import inverse
y1 = torch.from_numpy(y1)
def gauss_kernel(x, xd, theta1, theta2):
k = theta1 * torch.exp(- (x-xd)**2/ theta2)
return k
def get_covariance(xs, theta1, theta2, theta3):
cov = []
for i in xs:
k = gauss_kernel(
i,
torch.Tensor(list(xs)).float(),
theta1, theta2
)
cov.append(k)
cov = torch.stack(cov)
cov = cov + torch.eye(cov.shape[0]) * theta3
return cov
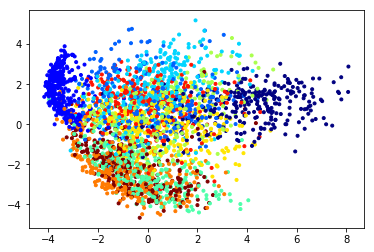
適当なパラメータで作った共分散行列は以下.
左上の部分($S_{11}$)は$y_1$に関する分散共分散を表している.
日付順に並んでいるので対角線,つまり,近い日付との共分散が大きくなっていることがわかる.
また,右下の部分($S_{22}$)は$y_2$に関する共分散を表しており,ここも同じ傾向がある.
右上($S_{12}$),左下の部分($S_{21}$)は$y_1$,$y_2$の間の共分散を表している.
ランダムに間引いて$y_1$と$y_2$を分けているので,日付が近い部分がこういう感じで現れている.
cov = get_covariance(xs=xs, theta1=1, theta2=1, theta3=1)
sns.heatmap(cov, square=True, cmap="viridis", cbar=None)
plt.vlines(x1.shape[0]-1, ymin=0, ymax=xs.shape[0], lw=1, colors="gray")
plt.hlines(x1.shape[0]-1, xmin=0, xmax=xs.shape[0], lw=1, colors="gray")
plt.xlim(0, xs.shape[0])
plt.ylim(xs.shape[0], 0)
plt.show()

この共分散行列を用いて条件付き確率 $p(y_2 | y_1) = \mathcal{N}(S_{21}S_{11}^{-1}(y_1-\bar{y}) + \bar{y}, S_{22} - S_{21}S_{11^{-1}}S_{12})$を求める.
def conditional_dist(theta1, theta2, theta3, x1, y1, x2, y2=None):
xs = np.r_[x1, x2]
y1_mean = torch.mean(y1)
cov = get_covariance(xs, theta1, theta2, theta3 )
y1_indexes = list(range(len(x1)))
y2_indexes = list(range(len(x1), len(x1) + len(x2)))
Sigma11 = cov[np.meshgrid(y1_indexes, y1_indexes)]
Sigma22 = cov[np.meshgrid(y2_indexes, y2_indexes)]
Sigma12 = cov[np.meshgrid(y2_indexes, y1_indexes)]
Sigma21 = cov[np.meshgrid(y1_indexes, y2_indexes)]
mean = y1_mean + Sigma21 @ inverse(Sigma11) @ (y1-y1_mean)
variance = Sigma22 - Sigma21 @ inverse(Sigma11) @ Sigma12
if y2 is None:
return mean, variance
norm = torch.distributions.MultivariateNormal(loc=mean, covariance_matrix=variance)
return mean, variance, norm.log_prob(y2)
def data4plot(x1, x2, y1, theta1, theta2, theta3):
xs = np.r_[x1, x2]
means = []
variances = []
plot_range_y2 = torch.stack([torch.linspace(torch.min(y1)-5,
torch.max(y1)+5, 1000)]).t()
list_log_probs = []
for i in tqdm(range(len(xs))):
mean, variance, log_prob = conditional_dist(theta1=theta1, theta2=theta2,
theta3=theta3,
x1=np.array(x1), y1=y1,
x2=np.array([i]), y2=plot_range_y2)
means.append(mean.data.numpy())
variances.append(variance.data.numpy())
list_log_probs.append(log_prob)
means = np.array(means).reshape(-1)
variances = np.array(variances).reshape(-1)
return means, variances, torch.stack(list_log_probs).t(), plot_range_y2
means, variances, log_probs, plot_range_y2 = data4plot(x1, x2, y1, theta1=1, theta2=1, theta3=1)
ids = list(range(len(x1) + len(x2)))
XX, YY = np.meshgrid(ids, plot_range_y2.data.numpy()[:,0])
plt.contourf(XX, YY, np.exp(log_probs), alpha=1)
plt.plot(x1, y1.data.numpy(), c="C1", marker=".")
plt.show()

なんかだめそうである.一部を拡大してみると以下.
plt.contourf(XX, YY, np.exp(log_probs), alpha=1)
plt.plot(x1, y1.data.numpy(), c="C1", marker=".")
plt.xlim(60, 120)
plt.show()
plt.contourf(XX, YY, np.exp(log_probs), alpha=1)
plt.plot(x1, y1.data.numpy(), c="C1", marker=".")
plt.xlim(160, 220)
plt.show()


適当に作ったパラメータでは観測データと結構ずれていてだめそうである.
上では共分散行列をカーネルの形で与えることで,観測データを1つの多変量ガウス分布として表し,各日$x_i$での平均気温の確率$p(y_2|y_1)$を求めた.
しかし,適当に与えたカーネルのパラメータでは平均気温の変動を正しく捉えることができていない部分があった.
これはカーネルのパラメータ$\theta_1$, $\theta_2$,$\theta_3$を適切な値に設定できていないことが原因であると考えられる.
そこで,これらを観測データの対数尤度$\log p(y_1 | x_1;\theta)$を最大化するように勾配法を用いて更新する.
参考にした本ではL-BFGSとかを使うとかいてあるが,今回は簡単にAdamを使ってパラメータを更新した.
また,$\theta$は全て0以上の値なので,$\theta_i = \exp(η_i), i=1,2,3$として$η_i$を更新することにした.
from torch.optim import LBFGS, Adam
from random import shuffle
eta1 = torch.Tensor([1]).float()
eta2 = torch.Tensor([1]).float()
eta3 = torch.Tensor([1]).float()
eta1.requires_grad = True
eta2.requires_grad = True
eta3.requires_grad = True
optimizer = Adam([eta1, eta2, eta3], lr=0.01)
hist_eta1 = []
hist_eta2 = []
hist_eta3 = []
hist_log_probs = []
for i in tqdm(range(1000)):
if eta3 < -5:
eta3.data = torch.Tensor([-5])
theta1 = torch.exp(eta1)
theta2 = torch.exp(eta2)
theta3 = torch.exp(eta3)
hist_eta1.append(float(eta1.data.numpy()))
hist_eta2.append(float(eta2.data.numpy()))
hist_eta3.append(float(eta3.data.numpy()))
means, variances, log_probs = conditional_dist(theta1, theta2, theta3,
x1, y1,
x1, y1)
optimizer.zero_grad()
(-log_probs).backward()
optimizer.step()
if i==900:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
hist_log_probs.append(log_probs.data.numpy())
plt.plot(hist_eta1)
plt.show()
plt.plot(hist_eta2)
plt.show()
plt.plot(hist_eta3)
plt.show()



事前分布もおかずに最尤推定しているので,$\theta_3$ (観測のノイズの係数)が0に落ちていっている.
最尤推定で求めたパラメータを用いて,$y_2$の平均を求めると以下.
means, variances, log_probs, plot_range_y2 = data4plot(x1, x2, y1,
theta1=theta1, theta2=theta2,
theta3=theta3)
plt.plot(means)
plt.plot(x1, y1, marker=".")
plt.show()

先ほどのパラメータよりもできてそうである.
また,$y_2$の分布をプロットすると以下(観測がある点と観測がない点で値が違いすぎるのでheatmapでは書きにくかった).
薄い色が2σ,濃い色が1σの領域を表す.
一部を拡大したものをその下に示す.
plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.show()
plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.xlim(60, 120)
plt.show()
plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.xlim(160, 220)
plt.show()



観測が存在した点では観測点の一点のみ高い確率になり,観測が存在しなかった点では分布が広がっていることがわかる.
今回のように最尤推定すると,$\theta_3$を0に近づけていくので,今回のような分布に収束する.
試しに$\theta_3=0.1$で固定してみると以下のようになる.
from torch.optim import LBFGS, Adam
from random import shuffle
eta1 = torch.Tensor([1]).float()
eta2 = torch.Tensor([1]).float()
eta3 = torch.Tensor([-1]).float()
eta1.requires_grad = True
eta2.requires_grad = True
optimizer = Adam([eta1, eta2], lr=0.01)
hist_eta1 = []
hist_eta2 = []
hist_eta3 = []
hist_log_probs = []
for i in tqdm(range(2000)):
theta1 = torch.exp(eta1)
theta2 = torch.exp(eta2)
theta3 = torch.exp(eta3)
hist_eta1.append(float(eta1.data.numpy()))
hist_eta2.append(float(eta2.data.numpy()))
hist_eta3.append(float(eta3.data.numpy()))
means, variances, log_probs = conditional_dist(theta1, theta2, theta3,
x1, y1,
x1, y1)
optimizer.zero_grad()
(-log_probs).backward()
optimizer.step()
if i==900:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
hist_log_probs.append(log_probs.data.numpy())
plt.plot(hist_eta1)
plt.show()
plt.plot(hist_eta2)
plt.show()
plt.plot(hist_eta3)
plt.show()



means, variances, log_probs, plot_range_y2 = data4plot(x1, x2, y1,
theta1=theta1, theta2=theta2,
theta3=theta3)
plt.plot(means)
plt.plot(x1, y1, marker=".")
plt.show()

plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.show()
plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.xlim(60, 120)
plt.show()
plt.plot(means)
plt.fill_between(range(len(means)), means-variances**0.5, means+variances**0.5, facecolor="C0", alpha=0.2)
plt.fill_between(range(len(means)), means-variances**0.5*2, means+variances**0.5*2, facecolor="C0", alpha=0.2)
plt.plot(x1, y1, marker=".")
plt.xlim(160, 220)
plt.show()



本当はパラメータに事前分布とかおいて事後分布を推定したほうがいいように思えるが,今回はここまで.
おわりに
ガウス過程と機械学習の3章までの内容についてコードを書いた.
無限次元とかよくわからないというか無限が何もわからないのでそのへんが理解できているのか怪しい.
GPLVMの実装もそのうちやりたい.
参考
ガウス過程と機械学習